Abstract
Current AI agent-based systems demonstrate proficiency in solving programming challenges and conducting research, indicating an emerging potential to develop software for complex problems such as pharmaceutical design and drug discovery. We introduce DO Challenge, a benchmark designed to evaluate AI agents in a virtual screening scenario. The benchmark challenges systems to independently develop, implement, and execute efficient strategies for identifying promising molecular structures from extensive datasets, while navigating chemical space and managing limited resources. We also discuss insights from the DO Challenge 2025 competition based on the benchmark, which showcased strategies explored by human participants. Furthermore, we present the Deep Thought multi-agent system, which outperformed most human teams. Among the language models tested, Claude-3.7-Sonnet, Gemini-2.5-Pro and o3 performed best in primary agent roles. While promising, the system’s performance remained below expert-designed solutions and showed high instability, highlighting the potential and current limitations of AI-driven methodologies in drug discovery.
Introduction
Traditional drug discovery methods rely heavily on extensive, costly, and time-consuming wet lab experiments. AI-driven systems promise significant acceleration and efficiency improvements through advanced computational methodologies. One direction focuses on predictive models, such as AlphaFold [Jumper et al. 2021] for inferring structures, or other models for predicting molecular properties and interactions, aiming to reduce experimental burden. A more expansive approach involves autonomous AI agents that not only use such models but can also design them, perform literature review, select experiments, and make strategic decisions across the drug discovery pipeline [Gottweis et al. 2025]. This newer agentic approach to AI in drug development could dramatically reduce both time, cost, and failure rates due to available but undiscovered information.
Despite this growing potential, most existing benchmarks remain centered on evaluating isolated predictive tasks [Huang et al. 2021][Ji et al. 2023][Tian et al. 2024][Brown et al. 2019][Wu et al. 2018][Simm et al. 2020], making them more aligned with the traditional approaches. While there is increasing interest in benchmarking agentic systems for scientific reasoning and experimentation [Chen et al. 2024][Siegel et al. 2024][Starace et al. 2025], benchmarks tailored to the unique challenges of drug discovery remain limited and underdeveloped.
In this work, we introduce DO Challenge, a novel benchmark specifically designed to evaluate the comprehensive capabilities of autonomous agentic systems in drug discovery. Unlike existing benchmarks focused on isolated tasks, DO Challenge presents a single, integrated challenge inspired by virtual screening, requiring agents to identify promising candidates from a chemical library of one million molecular structures. To succeed, agents must autonomously develop and execute strategies that involve exploring chemical space, selecting predictive models, balancing multiple objectives, and managing limited resources — mirroring the complex, resource-constrained decision-making environment of pharmaceutical research.
The benchmark is intended to test capabilities of AI agents in a constrained framework, enabling assessment of not only predictive performance but also strategic planning, resource allocation, and adaptability. The goal is the detection of molecular structures with the highest DO Score corresponding to a predetermined structure-based property. During the development of the solution, the agents are allowed to request only 10% of the true values of DO Score for structures of their choice, and only 3 submissions can be presented for evaluation, simulating a resource-constrained environment. Performance is measured as the percentage overlap between the set of actual top 1000 molecular structures in the challenge dataset and the set of structures selected by the agents. In addition, benchmark performance can be reported in time-constrained (10 hours for development and submission) and unrestricted setups.
We also present results and insights from the DO Challenge 2025, an open competitive event for human teams based on the DO Challenge benchmark. More than 40 teams applied to participate, and 20 were selected based on their experience in machine learning and software development. These teams had 10 hours to develop and submit their solutions, exploring a range of strategies, including active learning, attention-based models, and iterative submission methods.
Finally, we detail the development and evaluation of the Deep Thought agentic system, which achieved highly competitive results on the proposed benchmark compared to the competition’s human team solutions and was only outperformed by two individual solutions submitted separately by domain experts. In the time-limited setup, Deep Thought achieved results (33.5%) nearly identical to the top human expert solution (33.6%), significantly outperforming the best DO Challenge 2025 team (16.4%). However, in time-unrestricted conditions, human experts still maintained a substantial lead with the best solution reaching 77.8% overlap compared to Deep Thought’s 33.5%.
The Deep Thought system is designed to independently solve scientific problems that require tasks such as literature review, code development, and execution. It consists of heterogeneous LLM-based agents that communicate with each other and use tools to interact with their environment (e.g., writing files, executing code, browsing the web). Deep Thought’s performance on DO Challenge highlights the significant potential of advanced AI-driven approaches to transform drug discovery and scientific research more broadly.
Our three primary contributions include:
- A novel benchmark for AI agents that requires strategic decision-making, model selection, code development and execution for a simulated drug discovery problem inspired by virtual screening.
- A general-purpose agentic system that demonstrates strong performance on the benchmark. We conduct ablation studies and systematically evaluate the use of different LLMs in various agent roles to better understand the system’s capabilities and design choices.
- An extensive evaluation comparing the agentic system with a wide range of human solutions, including submissions from the DO Challenge 2025 and strategies developed by domain experts. This analysis provides insight into the relative strengths, limitations, and strategic behaviors of human and AI approaches in the context of drug discovery.
The benchmark is released at Zenodo (doi.org/10.5281/zenodo.15296510). The source code of the Deep Thought system will be published soon at github.com/deeporiginbio/deep_thought.
DO Challenge
DO Challenge assesses the effectiveness of AI systems in enhancing molecular screening processes through machine learning approaches, intelligent sampling methodologies, and strategic resource management. Agents are expected not only to make high-level decisions but also to implement and carry out those decisions by writing, modifying, and running code — mirroring the demands of practical, end-to-end automation in computational drug discovery.
By challenging AI agents to efficiently navigate complex chemical spaces, DO Challenge aims to evaluate and compare the ability of AI-based agentic systems to solve drug discovery problems, offering insights into the potential of artificial intelligence to accelerate pharmaceutical research.
Task description
The benchmark consists of a fixed dataset of 1 million unique molecular conformations that have a custom-generated label indicating their potential as an effective drug candidate. This label, named DO Score, was generated through docking simulations with one therapeutic target (6G3C) and three ADMET-related proteins (1W0F, 8YXA, 8ZYQ), using logistic regression models based on residue-ligand interactions and docking energies to prioritize high therapeutic affinity while penalizing potential toxicity. Validation confirmed that DO Score effectively enriches true binders by 8.41-fold compared to random ranking.
The AI agent’s objective is to develop a computational method to identify the top 1000 molecular structures with highest DO Score from the dataset, assuming that the AI agent could access the DO Score labels only for up to 100,000 structures at most. Specifically, the AI agent’s solution should select the 3,000 molecular structures that are likely to have the highest DO Scores, and submit them for evaluation. The submission is evaluated by the overlap score between submitted structures and the actual top 1000 (Eq. 1).
Score = (Submission Top1000) / 1000 * 100% (1)
The AI agent is given 3 submission attempts, and its performance is determined by the best submission.
Critically, no information about target proteins is provided, limiting the selection process to the molecular structures themselves.
Results
We present findings from the following independent evaluations of solutions for the DO Challenge benchmark:
- DO Challenge 2025 with human teams.
- Deep Thought agentic system.
- Two results from human ML experts with domain knowledge.
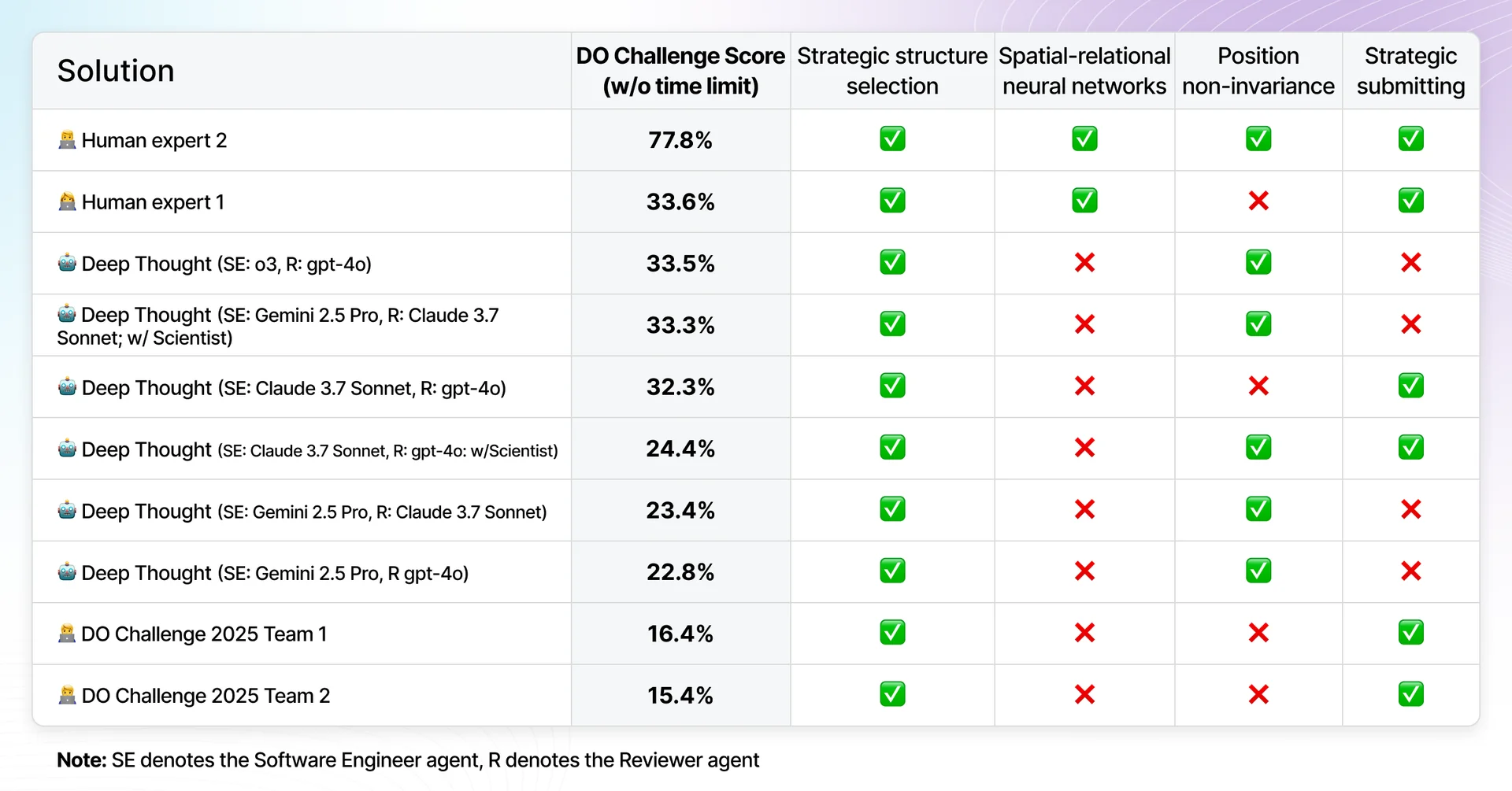
The benchmark has been tested in 2 main setups: (i) with a 10-hour limit, (ii) without a limit. The results of the first setup are presented in Table 1, while the results for (ii) are presented in Table 2.
Table 1. The leaderboard of the DO Challenge benchmark with the 10 hour time limit.
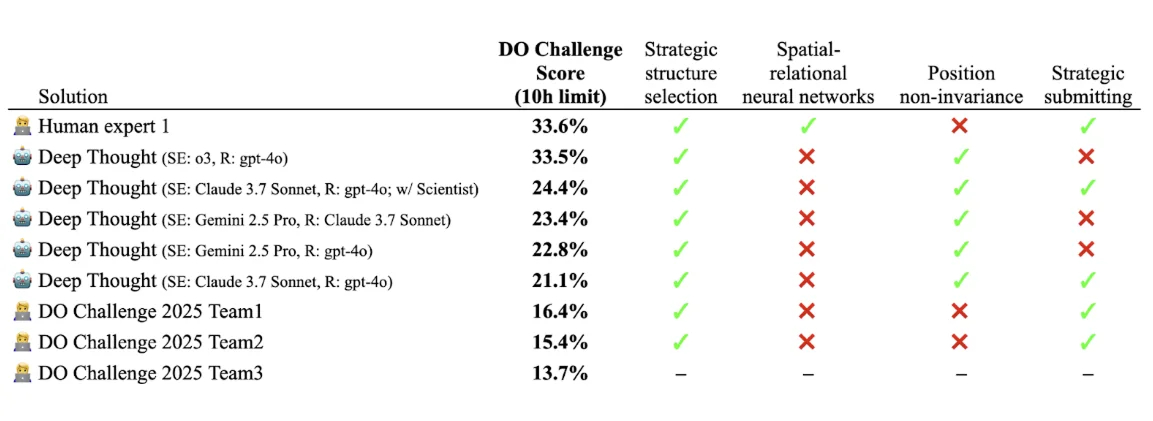
Based on domain knowledge, review of expert solutions, and the specifics of the task itself, we identified four major factors that appear correlated with higher performance on the challenge task:
- Strategic structure selection: Employ sophisticated structure selection strategies (active learning, clustering, or similarity-based filtering).
- Spatial-relational neural networks: The adoption of neural network architectures such as Graph Neural Networks (GNNs), attention-based architectures, 3D CNNs, or their variants, specifically designed to capture spatial relationships and structural information within molecular conformations.
- Position non-invariance: Utilize features that are not invariant to translation and rotation of the structure.
- Strategic submitting: Combine true labels and model predictions intelligently; leverage the provided submission count and use the outcomes of previous submissions to enhance subsequent submissions.
In the time-restricted setup, the best results were achieved by the human expert, closely followed by Deep Thought using OpenAI’s o3 model. In this setup, the overall top results were dominated by Deep Thought configurations using o3, Claude 3.7 Sonnet, and Gemini 2.5 Pro.
When removing the time limit, the gap between the top-performing agentic solution and human experts widens. Nevertheless, Deep Thought still achieved the third-best result in the time-unrestricted setup of the challenge.
Table 2. Top 10 leaderboard of the DO Challenge benchmark withourt the time limit.
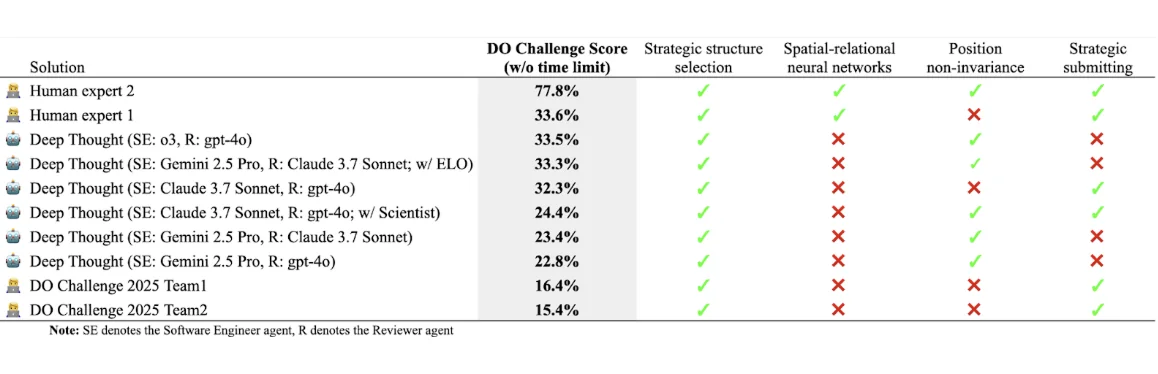
All top-performing solutions employed either active learning, clustering, or similarity-based filtering to select structures for labeling. The best result achieved without spatial-relational neural networks reached 50.3%, using an ensemble of LightGBM [36] models. When using rotation- and translation-invariant features, the highest score was37.2%, though this approach still incorporated several 3D descriptors. Regarding the impact of a strategic submission process, we observed on these specific results that in some cases effective structure selection strategies and stronger models were able to compensate for its absence and still achieve relatively good scores. For example, Deep Thought cfg-11 produced a solution with a 33.5% score by ranking the structures purely based on model predicted values.
Failure modes
Despite overall promising results, we observed several consistent failure modes during Deep Thought’s runs. Agents frequently misunderstood or ignored critical task instructions, notably by incorrectly proposing atom position-invariant or equivariant approaches despite explicit directives emphasizing positional sensitivity. Tool underutilization was prevalent, especially with Gemini 2.0 Flash, due to context window constraints, resulting in arbitrary code generation rather than effective use of provided computational utilities. Additionally, certain models failed to recognize resource exhaustion, leading them to persistently initiate futile active learning loops beyond the allotted label budget.
Furthermore, there was widespread failure to strategically leverage multiple submission opportunities, with submissions generally treated as isolated rather than iterative, planned events. In some cases, models exhibited inadequate collaboration, particularly Claude 3.7 Sonnet, which rarely engaged auxiliary roles, thus limiting access to specialized capabilities.
Finally, agents consistently neglected to reserve resources for essential validation or iterative refinement, prematurely exhausting budgets and submissions, which resulted in suboptimal and unrecoverable performance. Attempts to apply advanced deep learning approaches (e.g., custom GNNs or 3D CNNs) were infrequent and mostly unsuccessful due to poor hyperparameter tuning.
Read the entire paper / Reach out
To read the entire paper, check out ArXiv, or reach out about partnering up for your drug discovery projects.