Homology Modeling
Homology modeling provides structural information for targets whose structures are not experimentally determined, aiding in understanding their function and interactions. Structural models of targets can be used to identify potential binding sites for drug molecules.
Homology modeling, also known as comparative modeling, is a computational technique used to predict the three-dimensional structure of a protein based on known structures of homologues (templates). It is typically used when an experimental structure is not available, but close homologues are. More recently, deep learning protein prediction methods that utilize similar concepts are used. Homology modeling involves the following steps:
- Template Identification: Identifying one or more known homologous structures (templates) with significant sequence similarity to the desired target.
- Sequence Alignment: Aligning the target sequence with the template sequences.
- Model Building: Constructing a 3D model of the target based on the alignment and the structures of the templates.
- Model Refinement: Refining the model using energy minimization and/or molecular dynamics simulations.
- Model Validation: Assessing the quality of the model by e.g. retrieval rates of known ligands.
Importance in Computational Drug Discovery
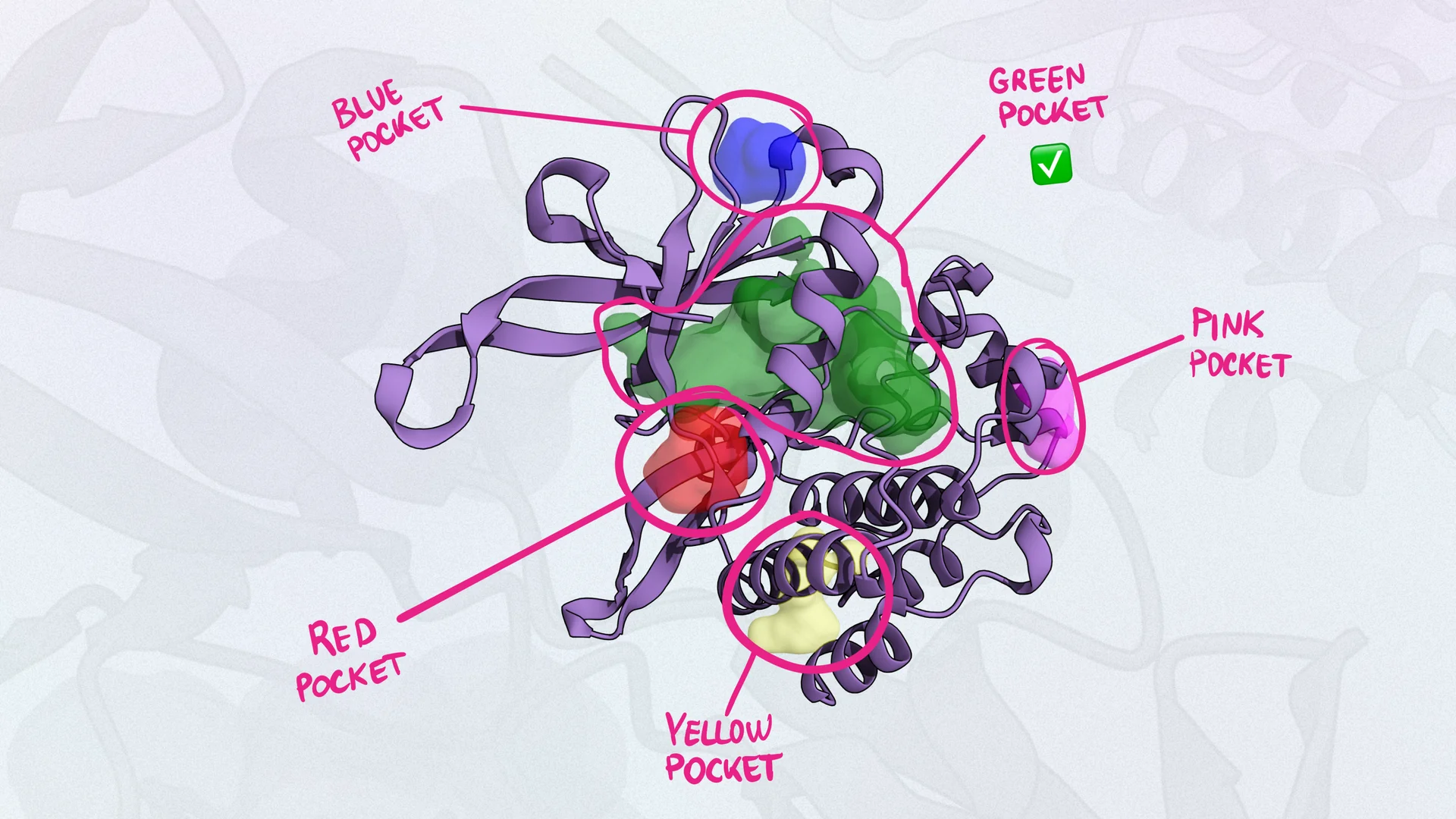
- Structure Prediction: Homology modeling provides structural information for targets whose structures are not experimentally determined, aiding in understanding their function and interactions.
- Target Identification: Structural models of targets can be used to identify potential binding sites for drug molecules.
- Ligand Docking: Homology models can be used for molecular docking studies that predict if and how small molecules interact with the target.
- Virtual Screening: Structural models enable structure-based virtual screening of large libraries of compounds to identify potential drug candidates (through docking).
- Rational Drug Design: Binding site structural information from homology models can facilitate the rational design of molecules with improved binding affinity and specificity.
Key Tools
-
Modeller: A widely-used program for homology modeling.
-
SWISS-MODEL: An automated server for homology modeling.
-
Phyre2: A web-based tool for predicting and analyzing protein structures using homology modeling.
-
I-TASSER: A server for protein structure and function prediction using an integrated approach of homology modeling and threading.
Literature
“Homology Modeling in Drug Discovery: Overview, Current Applications, and Future Perspectives”
-
Publication Date: 2018-10-08
-
DOI: 10.1111/cbdd.13388
-
Summary: Discusses the principles of homology modeling, its applications in drug discovery, and future perspectives in the field.
“Homology Modeling in Drug Discovery: Current Trends and Applications”
-
Publication Date: 2009-07-01
-
Summary: Reviews the current developments in homology modeling and its successful application in different stages of drug discovery.
“Homology Modeling in Drug Discovery – An Update on the Last Decade”
-
Publication Date: 2017-08-31
-
Summary: Provides an update on advancements in homology modeling techniques over the last decade and their impact on drug discovery.
“Combined Approach of Homology Modeling, Molecular Dynamics, and Docking: Computer-Aided Drug Discovery”
-
Publication Date: 2019-10-25
-
Summary: Reviews recent works employing a combined approach of homology modeling, molecular dynamics, and docking for structure-based drug design.
“Homology Modeling: An Important Tool for Drug Discovery”
-
Publication Date: 2015-08-03
-
Summary: Discusses the fundamentals and current state of homology modeling techniques and their applications in drug discovery.
“From Homology Modeling to the Hit Identification and Drug Repurposing: A Structure-Based Approach in the Discovery of Novel Potential Anti-Obesity Compounds”
- DOI: 10.1007/978-1-0716-1209-5_15
- Summary: Describes a structure-based approach integrating homology modeling for hit identification and drug repurposing.
“Homology Modeling of Coronavirus Structural Proteins and Molecular Docking of Potential Drug Candidates for the Treatment of COVID-19”
-
Publication Date: 2020-08-02
-
Summary: Models coronavirus proteins and docks potential drug candidates, identifying inhibitors like remdesivir, lopinavir, and ritonavir.
“Fragment-Based Virtual Screening Identifies Novel Leads Against Plasmepsin IX (PlmIX) of Plasmodium falciparum: Homology Modeling, Molecular Docking, and Simulation Approaches”
-
Publication Date: 2024-05-23
-
Summary: Uses homology modeling and virtual screening to identify novel inhibitors for Plasmepsin IX of Plasmodium falciparum.
“Homology Modeling Informs Ligand Discovery for the Glutamine Transporter ASCT2”
-
Publication Date: 2018-07-24
-
Summary: Provides insights into structural basis of substrate specificity for ASCT2, aiding in the design of selective inhibitors.
“Structure-Based Discovery of ABCG2 Inhibitors: A Homology Protein-Based Pharmacophore Modeling and Molecular Docking Approach”
-
Publication Date: 2021-05-23
-
Summary: Identifies potential ABCG2 inhibitors through a homology modeling and docking approach.